About Me
Hi, I'm Roman, a researcher in AI Safety at The AI Lab at The American College of Greece. This academic year, I'm graduating with a BSc (Hons) in Cybersecurity. After graduation, I plan to continue my academic and research career as a Ph.D. student.
My research focuses on AI alignment, trustworthiness, and security, to minimize the risks associated with the inevitable deployment of AI systems in critical domains including healthcare, cybersecurity, and robotics.
Currently, under the supervision of Prof. Ioannis T. Christou, I'm developing computer vision models for early diagnosis of acute lymphoblastic leukemia, and verifying the accuracy of learned representations based on model activations with gradient-weighted class activation mapping (Grad-CAM). Moreover, I'm actively developing my thesis on alignment assessment of vision-language-action (VLA) models with respect to safety regulations.
Publications
-
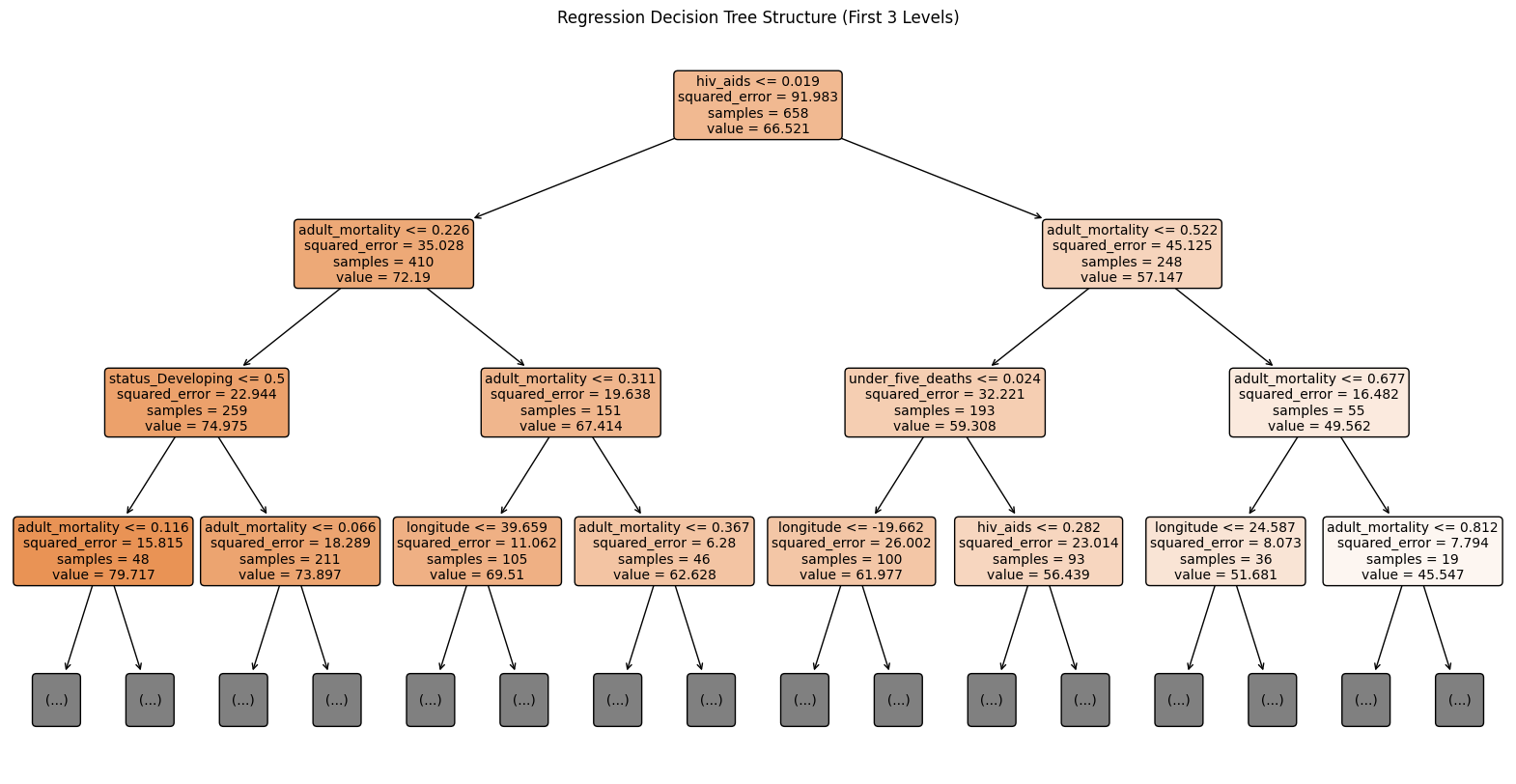
Interpretable Machine Learning for Life Expectancy Prediction
R. Dolgopolyi, I. Amaslidou, and A. Margaritou
arXiv, preprint, 2025.
[paper] [code] -
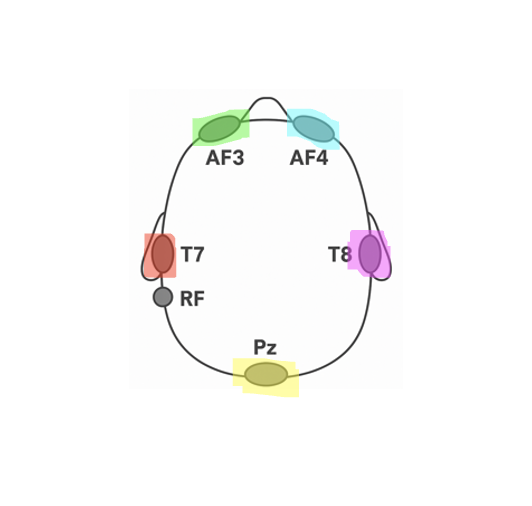
EEG Emotion Recognition Through Deep Learning
R. Dolgopolyi and A. Chatzipanagiotou
In Proceedings of the 22nd European, Mediterranean, and Middle Eastern Conference on Information Systems (Springer), 2025.
[paper] [code] -
Bridging Perception, Language, and Action: A Survey and Bibliometric Analysis of VLM & VLA Systems
R. Dolgopolyi and A. Tsevas
EurIPS'25 Workshop on the Science of Benchmarking and Evaluating AI, submitted for presentation, 2025.
[paper] -
Transparency of Autonomous Driving Algorithms
R. Dolgopolyi
AI and Ethics (Springer), submitted, 2025.
[paper]